
AI security tools identify and assess digital risks by using algorithmic analysis of observable data to detect patterns that deviate from expected behavior. These systems often ingest logs, network flows, endpoint telemetry, and application events, then apply methods such as statistical anomaly detection, behavioral baselining, and correlation engines to flag unusual activity. Outputs typically include alerts, risk scores, and contextual evidence intended to assist analysts in determining whether an event represents a potential incident. The description emphasizes methods and information flows rather than promises of prevention or absolute accuracy.
Architectures for these tools vary: some operate as inline network sensors, others as cloud-based analytics platforms, and some as integrated modules within security information and event management (SIEM) systems. Models used may be supervised, semi-supervised, or unsupervised and can incorporate rule-based logic alongside machine-learned components. Human review commonly complements automated signals to reduce incorrect actions. Limitations that often arise include data quality, model drift, and privacy constraints, which can affect detection sensitivity and the interpretability of outputs.

Data inputs and feature engineering are central to how AI security tools identify and assess digital risks. Raw telemetry is transformed into candidate features such as session durations, byte counts, command sequences, process creation trees, and inter-host connection graphs. Feature selection may be guided by domain experts and by automated methods that assess information gain. The representativeness of training or reference data often affects detection quality: if baseline datasets do not reflect current operational patterns, models may produce more false positives or negatives. Attention to timestamp synchronization, normalization, and enrichment is typically necessary to produce reliable analytic outcomes.
Detection methods used by these tools can vary by use case and available labels. Supervised models may be trained on labeled incident samples for specific threat types, while unsupervised approaches often detect novel deviations without prior examples. Semi-supervised and hybrid architectures frequently combine rule-based filters with machine learning to balance explainability and adaptability. Pattern recognition techniques, including clustering and sequence modeling, may identify lateral movement or command-and-control behaviors. Each method typically trades off sensitivity, specificity, and computational cost, and selection depends on operational priorities.
Risk scoring and prioritization help translate signals into analyst actions by assigning relative severity based on contextual factors. Scores often integrate attributes such as asset value, exploitability indicators, prevalence of observed behavior, and corroborating intelligence from external feeds. Scoring frameworks may be calibrated to organizational tolerance for risk and can include adjustable thresholds to manage alert volumes. Because risk assessments may rely on incomplete information, scores are typically presented with confidence indicators or provenance details so human reviewers can interpret the level of uncertainty when making response decisions.
Operational integration emphasizes the role of human oversight and feedback loops in sustaining effective detection and assessment. Automated tools commonly feed alerts into analyst workflows, ticketing systems, or incident response playbooks where triage, investigation, and corrective actions occur. Continuous retraining or model tuning may follow analyst validation to reduce recurring false positives. Privacy-preserving practices, role-based access controls, and retention policies are often applied to telemetry and model outputs to align analytics with legal and compliance constraints. These operational considerations shape how systems are deployed and maintained.
In summary, AI security tools identify and assess digital risks by converting diverse telemetry into signals, applying analytic models to detect deviations or known patterns, and producing scored outputs to guide human review. They may improve signal-to-noise ratios and support prioritization, yet they typically require careful data curation, tuning, and governance to perform effectively. The next sections examine practical components and considerations in more detail.
Various categories of AI security tools address different aspects of risk identification and assessment. Network-focused systems analyze packet flows and connection metadata to detect anomalous lateral movement or exfiltration patterns. Endpoint-focused agents collect process, file, and system call information to identify suspicious activity at the host level. Cloud-native analytics may monitor API calls and configuration changes in cloud environments. Each category typically employs distinct telemetry sources and detection techniques, and organizations often combine them to produce a broader view of potential risk.
Detection techniques within these tool categories can include statistical baselining, clustering, sequence analysis, and supervised classifiers. Statistical baselining looks for deviations from historical norms, while clustering can reveal groups of related events that may represent coordinated activity. Sequence analysis may detect unusual command chains or execution paths. Supervised classifiers can identify known malicious patterns when sufficient labeled examples exist. The selection among these techniques often reflects available data labels, computational resources, and the need for interpretability versus sensitivity.
Hybrid approaches that combine rule-based logic with machine learning are frequently used to balance precision and transparency. Rules can encode well-understood indicators of compromise or policy constraints, while machine learning can detect novel or subtle deviations that rules may miss. Combining methods may reduce false positives if rules filter obvious benign cases before applying probabilistic models. However, hybrid architectures introduce complexity in maintenance and require coordinated updating of rules and model parameters to remain effective over time.
When evaluating detection methods, practical considerations include computational cost, latency, and explainability. Some models may be suitable for near-real-time detection but require substantial compute resources, while others may run offline for strategic analysis. Explainability is important for analyst trust: methods that provide interpretable features or provenance traces often enable more effective investigations. These factors typically guide tool selection and deployment strategy rather than implying a single preferred solution.
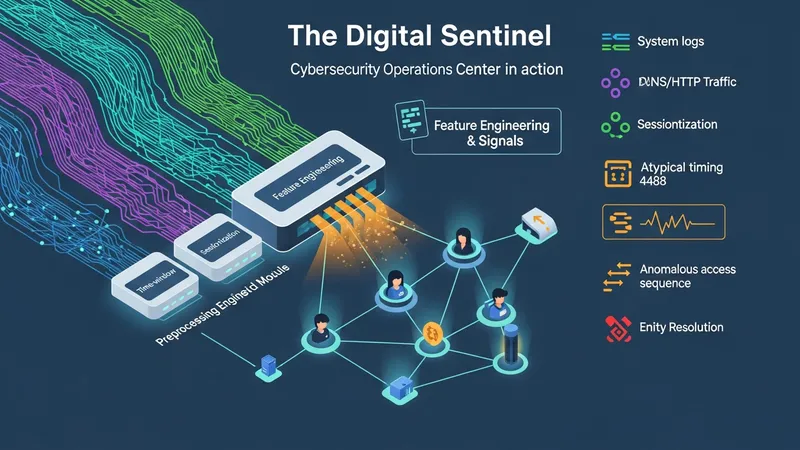
Telemetry diversity and quality are foundational to how intelligent systems assess digital risks. Common inputs include system logs, DNS and HTTP request records, authentication events, process creation logs, and application traces. Good feature engineering transforms these raw inputs into signals such as uncommon port usage, atypical timing patterns, or anomalous access sequences. Time-window selection, sessionization, and entity resolution (linking IPs, users, and devices) are typical preprocessing steps that can influence detection sensitivity and analytic relevance.
Contextual enrichment often supplements raw telemetry to improve interpretability and prioritization. Enrichment sources may include asset inventories, vulnerability databases, configuration management data, and threat intelligence feeds. For example, combining an anomalous login with a known vulnerable asset or a recent advisory about an exploit can raise the priority of a detection. Enrichment helps models and analysts differentiate between benign unusual events and signals that merit deeper investigation, though it also depends on the timeliness and accuracy of the external data sources used.
Data governance and privacy considerations commonly shape what inputs are available and how they are processed. Masking, aggregation, and selective retention are techniques that may be applied to reduce exposure of sensitive information while preserving analytic value. Data completeness and labeling availability often determine whether supervised learning is feasible; where labels are scarce, unsupervised or semi-supervised methods may be preferable. These trade-offs typically influence both technical design and policy decisions around telemetry collection.
Feature selection and validation practices help manage model performance over time. Analysts may monitor feature importance measures, perform ablation tests, or simulate attack scenarios to assess how features contribute to detection. Regular review of feature drift and recalibration processes can mitigate performance degradation as operational patterns evolve. These validation activities are often framed as ongoing considerations to maintain effective identification and assessment of digital risks rather than one-time setups.
Risk scoring frameworks convert disparate signals into an interpretable metric that aids prioritization. Scores can incorporate dimensions such as exploitability indicators, asset criticality, number of corroborating signals, and temporal urgency. Weighting schemes are typically configurable so organizations can reflect their operational priorities. Scores may be presented with metadata indicating contributing signals and confidence levels to help analysts determine whether to escalate an event. This practice supports resource allocation by focusing attention on higher-scoring items while acknowledging inherent uncertainty.
Prioritization strategies often combine automated scoring with analyst input to tune alert routing and noise reduction. For example, low-severity alerts may be batched for periodic review while higher-severity events trigger immediate triage workflows. Thresholds used to classify severity are commonly adjusted based on observed false-positive rates and analyst capacity. Over time, feedback loops that incorporate analyst dispositions can recalibrate scoring to better align automated priorities with operational realities.
Alert handling processes benefit from contextual detail accompanying scores. Context can include recent activity timelines, correlated events across systems, and any enrichment data that supports quicker decision-making. Well-structured context reduces investigation time by surfacing relevant evidence. However, excessive context or poorly organized details may overwhelm analysts, so balance and thoughtful presentation of contributing factors are typical design considerations in alerting systems.
Evaluation of scoring systems often uses measured metrics such as precision, recall, and time-to-triage, treated as indicators rather than guarantees of future performance. Regular assessment under simulated scenarios or historical replay can reveal how scoring behaves under different conditions and whether thresholds require adjustment. These assessments are usually framed as part of continuous improvement practices to maintain alignment between automated risk assessments and human operational needs.
Deploying AI security tools into operational environments commonly involves phased integration, validation, and governance steps. Pilot deployments often run models in parallel with existing detection systems to compare outputs without affecting live workflows. This approach may reveal practical issues such as telemetry gaps, latency, or unexpected false positives. Integration with ticketing and case management systems typically supports analyst workflows, while documented procedures for model updates and rollback are recommended as part of prudent operational practice.
Model evaluation and monitoring focus on performance metrics and drift detection. Typical metrics include true positive and false positive rates, alert volumes, and mean time to detection. Continuous monitoring can detect when models produce increasing false positives or when data distributions shift, indicating a need for retraining or feature adjustment. Such monitoring is usually implemented as an ongoing activity rather than a one-off check to ensure models remain effective as environments change.
Governance and explainability are central to maintaining trust and compliance. Explainable outputs, provenance records, and audit trails assist in regulatory reviews and internal accountability. Policies that specify acceptable data use, retention intervals, and access controls help align analytics with privacy and legal requirements. Where automated actions are possible, governance often prescribes human review for higher-risk categories to preserve oversight and reduce the chance of inappropriate automated interventions.
Continuous improvement practices typically combine analyst feedback, simulated testing, and periodic policy review. Feedback from incident investigations can be used to refine detection rules and model features, while tabletop exercises may surface gaps in integration or response playbooks. These iterative activities help align AI-driven identification and assessment with evolving threat landscapes and operational needs, emphasizing sustained governance and evaluation over time.